I was playing some kind of video game in which I had reached a point where you got on a platform which would take you to an underground world. The art was very cartoonish. I had a thought that I really should have saved my game before I had gotten on this platform, but, decided to proceed ahead.
The underground realm was "Owl village" which struck me as a little strange as it was underground and Owls tend to fly. I then saw that there was something about characters from Secret of NIMH, and I pondered how it was that the game developers had gotten the rights to use those characters.
Note
Now that I think of it, "The Great Owl" in Secret of NIMH did in fact, live underground during the day.
At that point some sort of bridge broke and I got a message that said you had to pay in order to play the rest of the game, and the free trial was over. Puzzled, I went to write about this. I was editing a section called "COMPLICATIONS" in a long text file.
Note
Not that I'm sure what it was I was writing about, I have a vague feeling that the text file was a Walk-Through for the game I was playing.
As I was editing the paragraph, my attention turned to a web page up that was troubling me. It was an article about how AT&T was blocking, editing, and filtering certain network traffic. I was viewing it as a text file in Google Cache.
Note 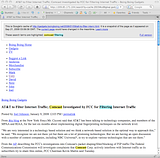
It looked a bit like this article on a similar topic:
...though what I was looking at was worse news about ISP corruption. The URL for the original site was something like ø.A6aAe9A.ø (possibly .com, but also possibly not). The Google Cache URL was something ugly, like the above is http://209.85.173.104/search?q=cache:Z83SWu88gkwJ:gadgets.boingboing.net/2008/01/09/att-to-filter-intern.html+comcast+filtering&hl=en&gl=us&strip=1
I decided I was going to post a link to that article in my document, even though it had nothing to do with what I was writing about. People had to be informed about this. But the link was too long, and I was worried that the Google Cache might go stale if I used that. So I followed through to the site that was hosting the original story.
When I clicked on the link that was the supposed source of the cache, the article no longer worked. It was instead some kind of entertainment site, with videos. They were thoroughly bizarre, like of Edward Norton completely naked doing some kind of pole dance with a stripper in a brightly lit room...as if they were performing some kind of circus. It was slapstick, and another stripper on another podium had a heel break and fell face first on the ground. People were laughing about this.
As I clicked around I started seeing a lot more domain suffixes, like ".Debug" and ".Debug.SDK". Another thing I ran into was that after visiting a couple pages on the site, I got a page that said I'd viewed the maximum number of free pages and would have to now pay for an account.
Note
Though it is generally the case that websites don't "sense" who is visiting and ration their pages, this is technologically possible to do. In fact, I had just seen it done earlier today by the magazine "The Motley Fool", which allows an inbound clicker one page view before they are forced to register.
By this time I was aware that I was dreaming. I pondered the relationship between this Edward Norton and the actor. I decided I didn't trust any of the links and I was just going to copy and paste the content of the article into the text file, since that was probably the most important thing I could do while I was there.
Then I noticed I was having trouble controlling my body. As an experiment, I thought to roll around in my "dream bed" in order to try and figure out which way I was actually sleeping. I couldn't really figure it out, and while I was doing so a small fox terrier come from the side of the bed who began biting my neck and I awoke.